Topics
a la mode
AI
Amazon

Image Credits:Credit: kynny / Getty Images
Apps
Biotech & Health
Climate

Image Credits:Google
Cloud Computing
commercialism
Crypto
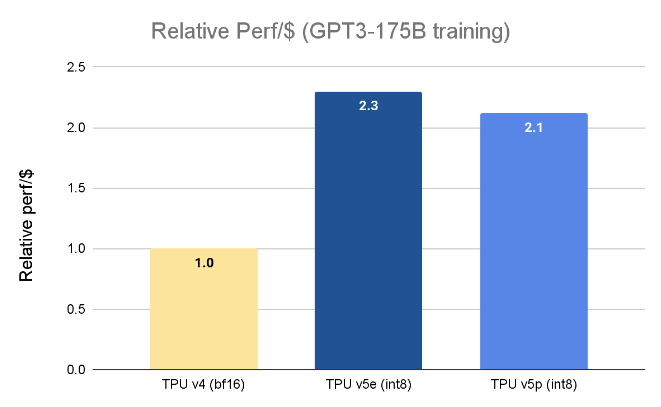
Image Credits:Google
Enterprise
EVs
Fintech
Fundraising
Gadgets
Gaming
Government & Policy
ironware
layoff
Media & Entertainment
Meta
Microsoft
Privacy
Robotics
Security
Social
distance
startup
TikTok
Transportation
Venture
More from TechCrunch
event
Startup Battlefield
StrictlyVC
Podcasts
video
Partner Content
TechCrunch Brand Studio
Crunchboard
Contact Us
Google today announced the launch of its newGeminilarge language model ( LLM ) and with that , the company also establish its new Cloud TPU v5p , an update version of its Cloud TPU v5e , whichlaunchedinto general availability earlier this twelvemonth . A v5p pod consists of a sum of 8,960 chips and is second by Google ’s fast interconnect yet , with up to 4,800 Gpbs per chip .
It ’s no surprisal that Google assure that these chip are significantly faster than the v4 TPUs . The team claims that the v5p features a 2x improvement in floating-point operation and 3x improvement in high - bandwidth memory . That ’s a mo like comparing the new Gemini model to the aged OpenAI GPT 3.5 example , though . Google itself , after all , already moved the state of the graphics beyond the TPU v4 . In many ways , though , v5e pods were a fleck of a downgrade from the v4 pod , with only 256 v5e chips per pod versus 4096 in the v4 seedpod and a totality of 197 TFLOPs 16 - bit floating point in time performance per v5e chip versus 275 for the v4 crisp . For the new v5p , Google promises up to 459 TFLOPs of 16 - bit floating point carrying into action , back by the fast interconnect .
Google says all of this entail the TPU v5p can train a large oral communication model like GPT3 - 175B 2.8 times faster than the TPU v4 — and do so more cost - in effect , too ( though the TPU v5e , while slower , really extend more comparative functioning per dollar than the v5p ) .
“ In our early stage usage , Google DeepMind and Google Research have keep 2X speedups for LLM training workloads using TPU v5p chips liken to the performance on our TPU v4 generation , ” pen Jeff Dean , main scientist , Google DeepMind and Google Research . “ The racy bread and butter for ML Frameworks ( JAX , PyTorch , TensorFlow ) and orchestration tools enables us to surmount even more expeditiously on v5p . With the 2nd genesis of SparseCores we also see significant betterment in the performance of embeddings - hard workloads . TPUs are vital to enable our largest - scale research and engineering effort on cutting edge models like Gemini . ”
The new TPU v5p is n’t generally useable yet , so developers will have to reach out to their Google account director to get on the listing .
