Topics
Latest
AI
Amazon

Image Credits:TechCrunch
Apps
Biotech & Health
Climate

Image Credits:Google
Cloud Computing
Commerce
Crypto
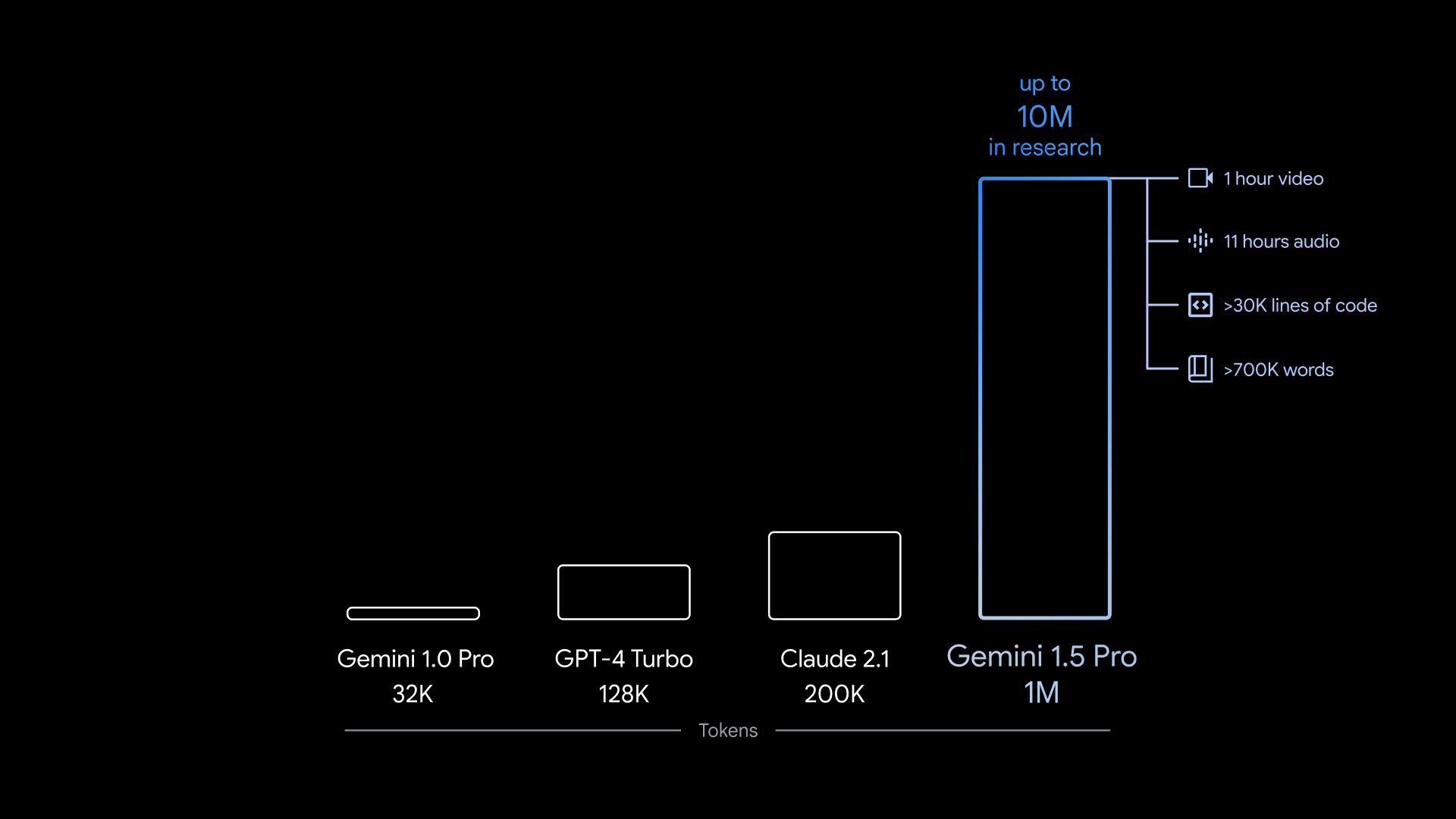
Image Credits:Google
Enterprise
EVs
Fintech
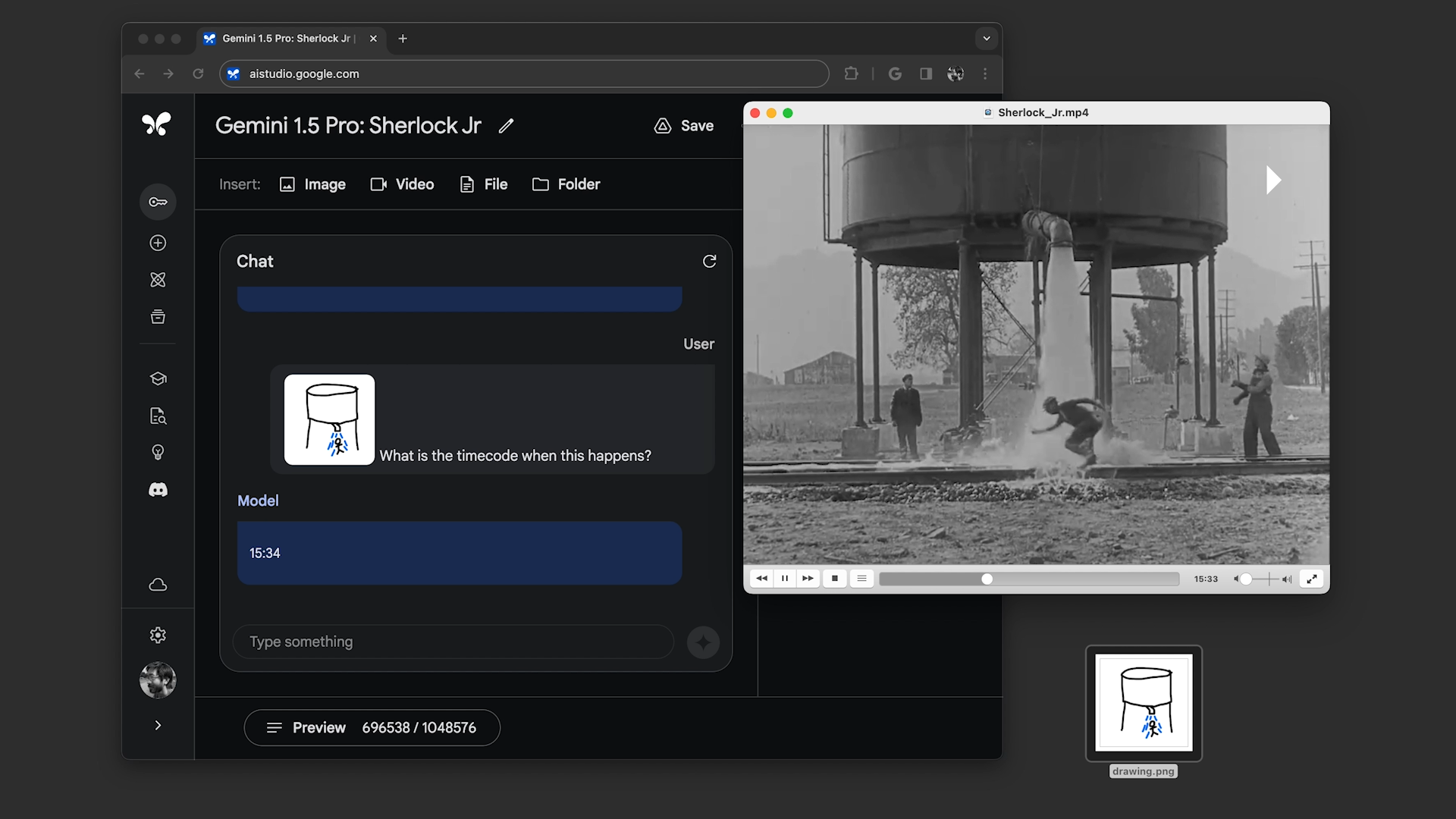
Image Credits:Google
Fundraising
widget
Gaming
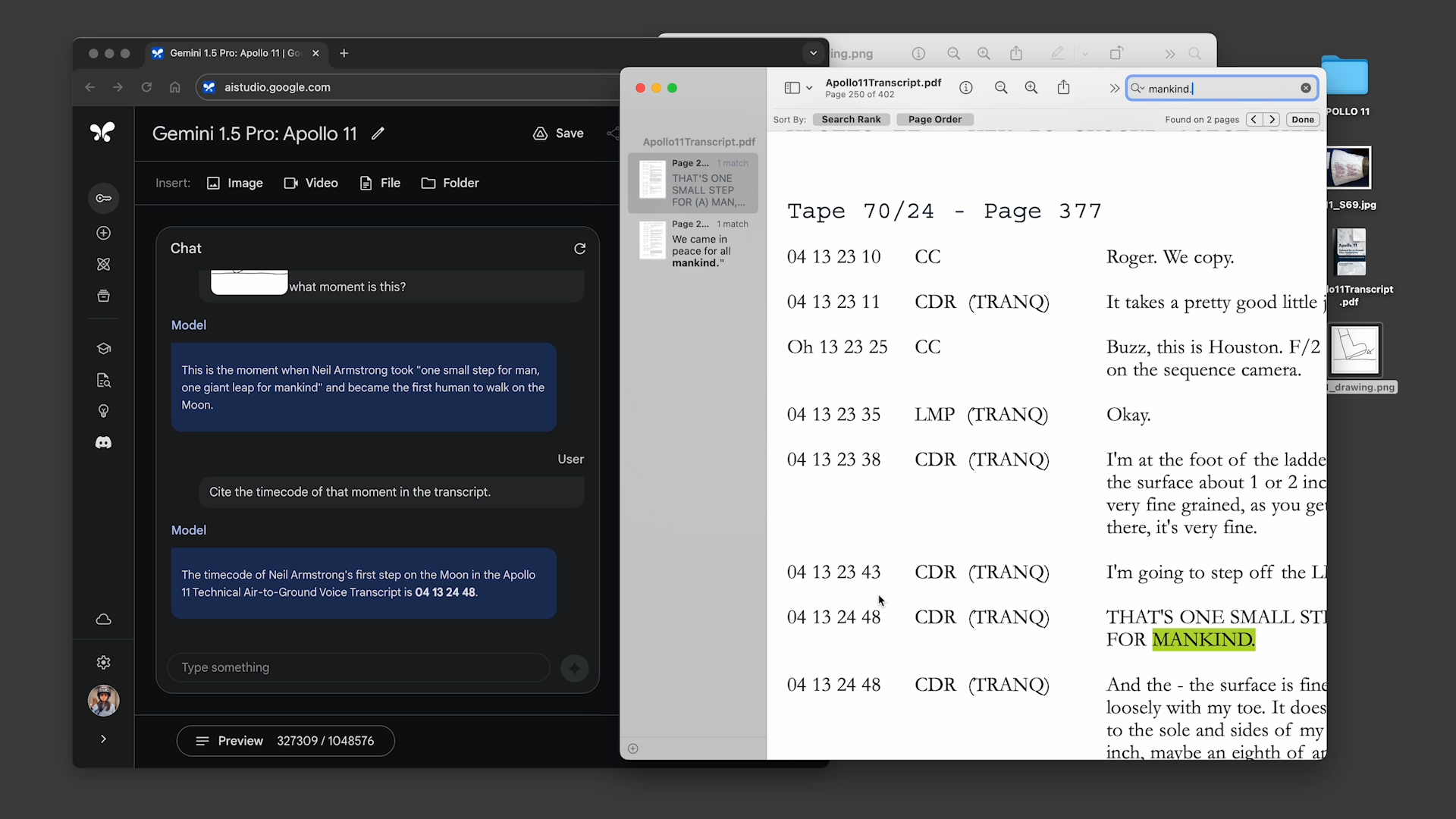
Image Credits:Google
Government & Policy
Hardware
Layoffs
Media & Entertainment
Meta
Microsoft
Privacy
Robotics
Security
Social
Space
inauguration
TikTok
Transportation
Venture
More from TechCrunch
case
Startup Battlefield
StrictlyVC
newssheet
Podcasts
video recording
Partner Content
TechCrunch Brand Studio
Crunchboard
get through Us
Last October , a research paperpublishedby a Google information scientist , the CTO of Databricks Matei Zaharia and UC Berkeley prof Pieter Abbeel posited a elbow room to let GenAI example — i.e. models along the lines of OpenAI’sGPT-4andChatGPT — to take in far more datum than was previously possible . In the study , the atomic number 27 - generator demonstrated that , by removing a major memory constriction for AI models , they could enable model to process one thousand thousand of run-in as opposed to hundreds of thousand — the maximum of the most subject models at the prison term .
AI inquiry moves tight , it seems .
Today , Google harbinger the release of Gemini 1.5 Pro , the newest member of itsGeminifamily of GenAI poser . Designed to be a drop - in replenishment for Gemini 1.0 Pro ( which formerly went by “ Gemini Pro 1.0 ” for reasons have it off only to Google ’s labyrinthine marketing weapon system ) , Gemini 1.5 Pro is meliorate in a number of area compared with its harbinger , perhaps most significantly in the amount of data that it can process .
Gemini 1.5 Pro can take in ~700,000 words , or ~30,000 lines of code — 35x the amount Gemini 1.0 Pro can handle . And — the model being multimodal — it ’s not limited to text . Gemini 1.5 Pro can ingest up to 11 minute of audio or an hour of TV in a smorgasbord of unlike linguistic process .
To be clean , that ’s an upper bound .
The version of Gemini 1.5 Pro available to most developer and customer starting today ( in a circumscribed preview ) can only swear out ~100,000 words at once . Google ’s characterizing the large - data point - input Gemini 1.5 Pro as “ data-based , ” allowing only developers approved as part of a individual preview to fly it via the company ’s GenAI dev toolAI Studio . Several customers using Google’sVertex AIplatform also have memory access to the large - data - stimulant Gemini 1.5 Pro — but not all .
Still , VP of research at Google DeepMind Oriol Vinyals hail it as an accomplishment .
Join us at TechCrunch Sessions: AI
Exhibit at TechCrunch Sessions: AI
“ When you interact with [ GenAI ] role model , the selective information you ’re inputting and outputting becomes the context of use , and the longer and more complex your questions and interaction are , the longer the setting the exemplar need to be able to dish out with gets , ” Vinyals said during a press briefing . “ We ’ve unlocked long context in a middling massive agency . ”
Big context
A model ’s context , or linguistic context window , refers to input information ( e.g. textual matter ) that the fashion model considers before generating production ( e.g. extra textual matter ) . A simple question — “ Who won the 2020 U.S. presidential election ? ” — can serve as context , as can a moving picture script , e-mail or tocopherol - book .
Models with small context window incline to “ bury ” the content of even very recent conversations , leading them to veer off topic — often in problematic ways . This is n’t of necessity so with models with large contexts . As an added upside , large - context of use models can good grasp the narration flow of data they take in and generate more contextually rich answer — hypothetically , at least .
There have been other endeavor at — and experiments on — models with atypically gravid context windows .
AI startupMagicclaimedlast summertime to have acquire a bombastic language good example ( LLM ) with a 5 million - token context window . Twopapersin the past yr contingent modeling architectures ostensibly subject of scale to a million tokens — and beyond . ( “ Tokens ” are subdivided bit of raw data , like the syllables “ buff , ” “ Ta ” and “ tic ” in the word “ fantastic . ” ) And of late , a radical of scientist hailing from Meta , MIT and Carnegie Mellon developed atechniquethat they say removes the constraint on simulation context window size altogether .
But Google is the first to make a model with a context window of this sizing commercially available , beatingthe previous leader Anthropic ’s 200,000 - token context window — if a individual prevue counts as commercially usable .
Gemini 1.5 Pro ’s maximal linguistic context windowpane is 1 million tokens , and the version of the model more wide available has a 128,000 - token context windowpane , the same as OpenAI’sGPT-4 Turbo .
So what can one action with a 1 million - token context window ? Lots of affair , Google promises — like analyzing a whole computer code library , “ reason across ” lengthy document like contract bridge , hold up tenacious conversations with a chatbot and analyzing and equate content in videos .
During the briefing , Google showed two prerecorded demos of Gemini 1.5 Pro with the 1 million - token linguistic context windowpane enabled .
In the first , the demonstrator asked Gemini 1.5 Pro to search the copy of the Apollo 11 moon landing telecast — which comes to around 402 pageboy — for quotes hold in jokes , and then to find a prospect in the telecast that expect similar to a pencil sketch . In the second , the sales demonstrator told the model to search for scenery in “ Sherlock Jr. , ” the Buster Keaton film , going by description and another survey .
Gemini 1.5 Pro successfully completed all the tasks ask of it , but not particularly quickly . Each conduct between ~20 second gear and a mo to process — far longer than , say , the average ChatGPT query .
Vinyals says that the rotational latency will improve as the example ’s optimized . Already , the company ’s testing a edition of Gemini 1.5 professional with a10 million - tokencontext windowpane .
“ The rotational latency facet [ is something ] we ’re … working to optimise — this is still in an data-based stage , in a inquiry point , ” he said . “ So these issues I would say are present like with any other model . ”
Me , I ’m not so sure reaction time that poor will be attractive to many folks — much less paying customers . have to wait minutes at a time to search across a video does n’t sound pleasant — or very scalable in the nigh term . And I ’m touch on how the response time manifests in other applications , like chatbot conversations and analyzing codebases . Vinyals did n’t say — which does n’t instill much sureness .
My more optimistic colleague Frederic Lardinois pointed out that theoveralltime savings might just make the quarter round twiddling worth it . But I think it ’ll depend very much on the exercise case . For picking out a show ’s plot decimal point ? Perhaps not . But for finding the veracious screengrab from a movie shot you only hazily recall ? Maybe .
Other improvements
Beyond the expanded context windowpane , Gemini 1.5 Pro brings other , caliber - of - life upgrades to the tabular array .
Google ’s claiming that — in term of quality — Gemini 1.5 Pro is “ comparable ” to the current adaptation of Gemini Ultra , Google ’s flagship GenAI model , thanks to a fresh architecture comprise of small , specialized “ expert ” models . Gemini 1.5 Pro fundamentally conk out down labor into multiple subtasks and then delegates them to the appropriate expert model , deciding which task to delegate based on its own prevision .
MoE is n’t refreshing — it ’s been around in some shape for years . But its efficiency and flexibleness has made it an progressively democratic choice among framework vendors ( see : themodelpowering Microsoft ’s language translation service of process ) .
Now , “ comparable lineament ” is a bit of a nebulous descriptor . Quality where it concerns GenAI simulation , peculiarly multimodal ones , is toilsome to measure — in two ways so when the fashion model are gated behind private preview that keep out the military press . For what it ’s worth , Google claims that Gemini 1.5 Pro performs at a “ broadly similar level ” compared to Ultra on the benchmark the company uses todevelop LLM whileoutperforming Gemini 1.0 Pro on 87 % of thosebenchmarks . ( I ’ll remark that outperforming Gemini 1.0 Pro is alow legal community . )
Pricing is a grown interrogative sentence fall guy .
During the private prevue , Gemini 1.5 Pro with the 1 million - token context window will be devoid to use , Google say . But the company plans to introducepricing tiers in the near future that start at the standard 128,000 context windowpane and scale up to 1 million tokens .
I have to imagine the large context windowpane wo n’t come gimcrack — and Google did n’t allay fears by opting not to bring out pricing during the briefing . If pricing ’s in line withAnthropic ’s , it could cost $ 8 per million prompt keepsake and $ 24 per million generated keepsake . But perhaps it ’ll be lower ; stranger thing have bechance ! We ’ll have to hold off and see .
I inquire , too , about the implication for the rest of the models in the Gemini kin , chiefly Gemini Ultra . Can we ask Ultra fashion model upgrades roughly align with Pro upgrade ? Or will there always be — as there is now — an ill-chosen stop where the available Pro model are superior performance - impudent to the Ultra manikin , which Google ’s still market as the top of the blood line in its Gemini portfolio ?
Chalk it up to teething issuing if you ’re feeling charitable . If you ’re not , call it like it is : darn confusing .
