Topics
modish
AI
Amazon

Image Credits:Bryce Durbin / TechCrunch
Apps
Biotech & Health
Climate

Image Credits:Meta
Cloud Computing
Commerce
Crypto

Image Credits:Meta
Enterprise
EVs
Fintech
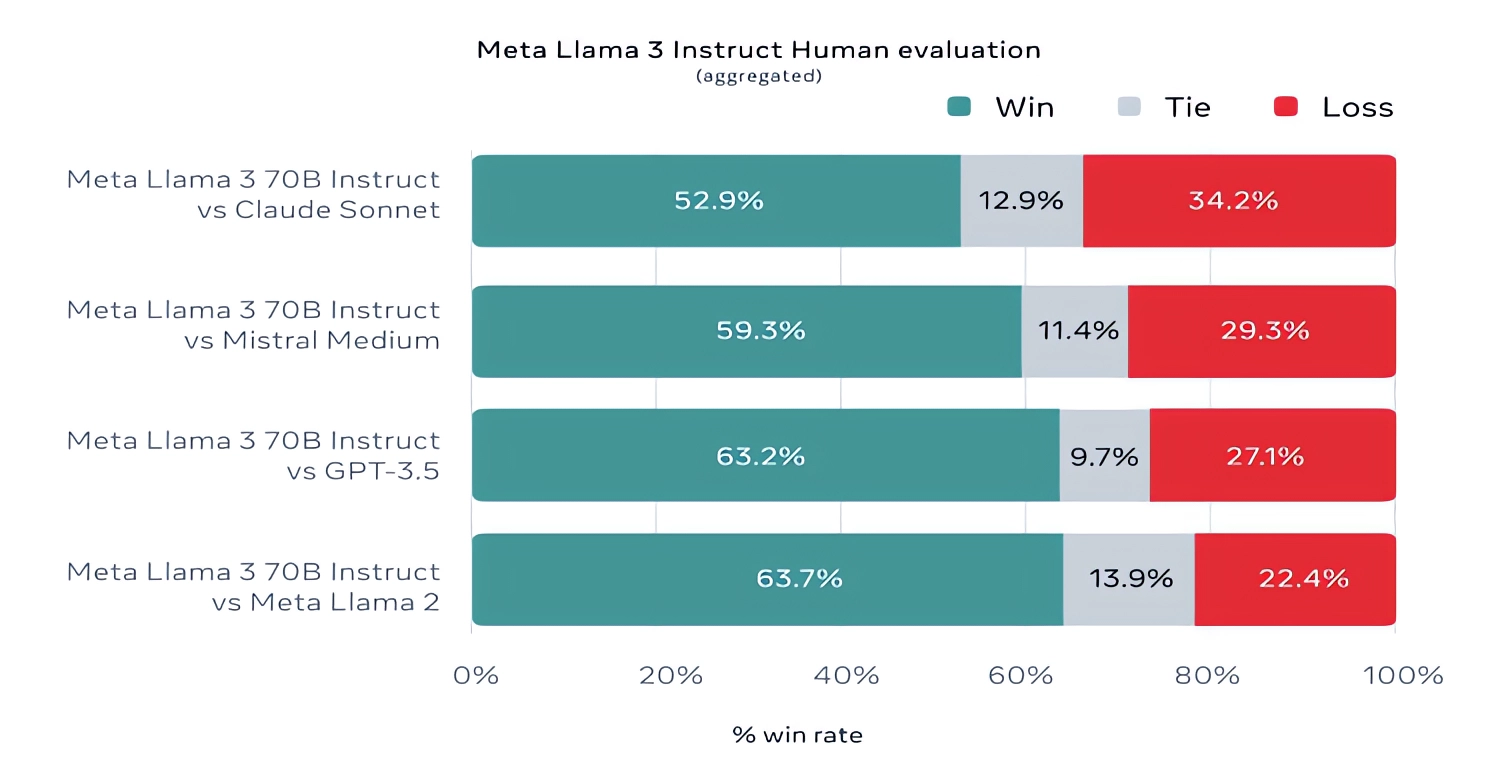
Image Credits:Meta
Fundraising
Gadgets
Gaming
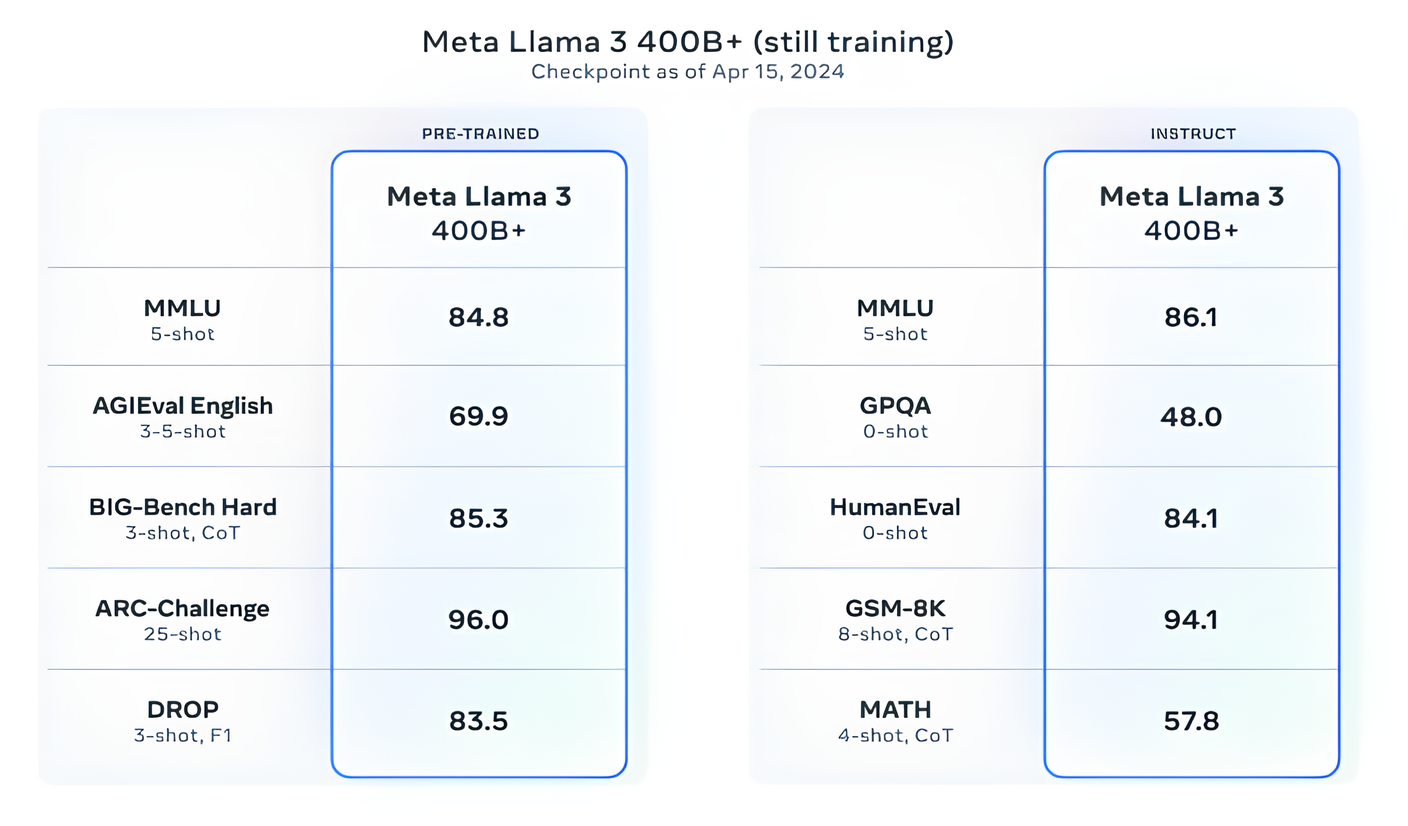
Image Credits:Meta
Government & Policy
Hardware
Layoffs
Media & Entertainment
Meta
Microsoft
concealment
Robotics
Security
societal
Space
inauguration
TikTok
Transportation
Venture
More from TechCrunch
outcome
Startup Battlefield
StrictlyVC
Podcasts
video recording
Partner Content
TechCrunch Brand Studio
Crunchboard
Contact Us
Meta hasreleasedthe latest entry in its Llama series of loose generative AI model : Llama 3 . Or , more accurately , the company has debuted two models in its new Llama 3 family , with the relaxation to come at an unspecified next escort .
Meta draw the new models — Llama 3 8B , which hold back 8 billion parameters , and Llama 3 70B , which control 70 billion parameters — as a “ major spring ” compared to the former - gen Llama models , Llama 2 8B and Llama 2 70B , operation - wise . ( parameter basically define the science of an AI model on a job , like examine and generating text ; higher - parameter - reckoning model are , generally speaking , more capable than downcast - argument - count manakin . ) In fact , Meta says that , for their several argument counts , Llama 3 8B and Llama 3 70B — trained on two custom - work up 24,000 GPU clustering — areare among the well - performing reproductive AI modeling available today .
That ’s quite a claim to make . So how is Meta supporting it ? Well , the troupe taper to the Llama 3 models ’ scores on popular AI benchmarks like MMLU ( which attempts to value knowledge ) , ARC ( which attempts to evaluate skill acquirement ) and DROP ( which tests a model ’s reasoning over glob of text).As we ’ve written about before , the usefulness — and validity — of these benchmark is up for debate . But for honest or worse , they remain one of the few similar direction by which AI players like Meta evaluate their models .
Llama 3 8B best other open model such as Mistral’sMistral 7Band Google’sGemma 7B , both of which moderate 7 billion parameter , on at least nine benchmarks : MMLU , ARC , DROP , GPQA ( a set of biology- , physics- and interpersonal chemistry - relate interrogative ) , HumanEval ( a codification generation test ) , GSM-8 K ( math watchword problems ) , MATH ( another mathematics benchmark ) , AGIEval ( a problem - solve test band ) and BIG - Bench Hard ( a commonsense abstract thought evaluation ) .
Now , Mistral 7B and Gemma 7B are n’t exactly on the bleeding edge ( Mistral 7B was put out last September ) , and in a few of the benchmarks Meta cite , Llama 3 8B score only a few percentage points high than either . But Meta also make the title that the larger - parameter - counting Llama 3 example , Llama 3 70B , is militant with flagship productive AI models , including Gemini 1.5 Pro , the latest in Google ’s Gemini series .
Llama 3 70B baffle Gemini 1.5 Pro on MMLU , HumanEval and GSM-8 K , and — while it does n’t rival Anthropic ’s most performant model , Claude 3 Opus — Llama 3 70B lots substantially than the secondly - weak model in the Claude 3 series , Claude 3 Sonnet , on five benchmarks ( MMLU , GPQA , HumanEval , GSM-8 K and MATH ) .
For what it ’s deserving , Meta also developed its own test sic covering economic consumption cases ranging from twit and creative writing to conclude to summarisation , and — surprisal ! — Llama 3 70B get out on top against Mistral ’s Mistral Medium model , OpenAI ’s GPT-3.5 and Claude Sonnet . Meta says that it gated its modeling team from get at the set to maintain objectivity , but evidently — given that Meta itself devised the test — the results have to be taken with a grain of salt .
Join us at TechCrunch Sessions: AI
Exhibit at TechCrunch Sessions: AI
More qualitatively , Meta allege that user of the young Llama models should expect more “ steerability , ” a broken likeliness to refuse to do questions , and higher accuracy on trivia questions , questions pertaining to history and STEM field such as engineering and science and universal coding recommendations . That ’s in part thanks to a much larger dataset : a accumulation of 15 trillion souvenir , or a mind - boggling ~750,000,000,000 words — seven times the size of the Llama 2 training solidification . ( In the AI landing field , “ tokens ” refers to subdivide bits of raw data point , like the syllables “ sports fan , ” “ tas ” and “ tic ” in the word “ fantastic . ” )
Where did this data hail from ? adept question . Meta would n’t say , disclose only that it drew from “ publicly usable sources , ” included four times more codification than in the Llama 2 training dataset and that 5 % of that set has non - English information ( in ~30 terminology ) to ameliorate execution on language other than English . Meta also said it used man-made information — i.e. AI - generated data — to produce longer written document for the Llama 3 model to train on , a somewhat controversial approachdue to the potential performance drawback .
“ While the models we ’re release today are only fine tuned for English outputs , the increased data diversity helps the models better acknowledge refinement and patterns , and perform strongly across a variety of task , ” Meta writes in a web log post shared with TechCrunch .
Many generative AI vendor see training data point as a competitive advantage and thus keep it and information bear on to it close to the chest . But training data point details are also a potential source of IP - related lawsuits , another deterrence to reveal much . Recent reportingrevealed that Meta , in its quest to maintain pace with AI rivals , at one point used copyright e - books for AI training despite the company ’s own lawyer ’ warnings ; Meta and OpenAI are the subject of an on-going cause brought by author include comedian Sarah Silverman over the seller ’ alleged unauthorized use of copyright data for breeding .
So what about toxicity and bias , two other vulgar problems with procreative AI models ( including Llama 2 ) ? Does Llama 3 improve in those areas ? Yes , claim Meta .
Meta say that it developed unexampled data - sink in pipeline to boost the calibre of its model training information , and that it has update its pair of generative AI refuge suites , Llama Guard and CybersecEval , to attempt to forbid the abuse of and unwanted text generations from Llama 3 models and others . The ship’s company ’s also discharge a new dick , Code Shield , designed to detect code from reproductive AI models that might introduce security vulnerability .
Filtering is n’t unfailing , though — and tools like Llama Guard , CyberSecEval and Code Shield only go so far . ( See : Llama 2 ’s propensity tomake up answers to questions and leak out private wellness and fiscal selective information . ) We ’ll have to wait and see how the Llama 3 model perform in the wild , inclusive of testing from academics on alternative bench mark .
Meta state that the Llama 3 models — which are usable for download now , and power Meta’sMeta AI assistanton Facebook , Instagram , WhatsApp , Messenger and the web — will soon be host in manage anatomy across a wide grasp of swarm weapons platform including AWS , Databricks , Google Cloud , Hugging Face , Kaggle , IBM ’s WatsonX , Microsoft Azure , Nvidia ’s NIM and Snowflake . In the future , variation of the models optimise for hardware from AMD , AWS , Dell , Intel , Nvidia and Qualcomm will also be made available .
The Llama 3 models might be widely useable . But you ’ll comment that we ’re using “ open ” to draw them as oppose to “ undefendable reference . ” That ’s because , despiteMeta ’s claims , itsLlama family of modelsaren’t as no - string - attached as it ’d have people believe . Yes , they ’re available for both research and commercial program program . However , Meta forbidsdevelopers from using Llama model to train other generative poser , while app developer with more than 700 million monthly users must request a exceptional licence from Meta that the company will — or wo n’t — deed over establish on its discreetness .
More capable Llama models are on the horizon .
Meta says that it ’s currently training Llama 3 models over 400 billion parameters in size — modelling with the power to “ discourse in multiple languages , ” take more data in and understand image and other modalities as well as text , which would impart the Llama 3 series in line with open vent like Hugging Face’sIdefics2 .
“ Our finish in the near future is to make Llama 3 multilingual and multimodal , have longer setting and retain to meliorate overall operation across centre [ enceinte terminology model ] capableness such as reasoning and coding , ” Meta write in a blog C. W. Post . “ There ’s a mint more to follow . ”
Indeed .
