Topics
late
AI
Amazon

Image Credits:Anthropic
Apps
Biotech & Health
mood
Image Credits:Anthropic
Cloud Computing
Commerce
Crypto
Image Credits:Anthropic
Enterprise
EVs
Fintech
Image Credits:Anthropic
Fundraising
Gadgets
punt
Image Credits:Anthropic
Government & Policy
Hardware

Image Credits:Anthropic
Layoffs
Media & Entertainment
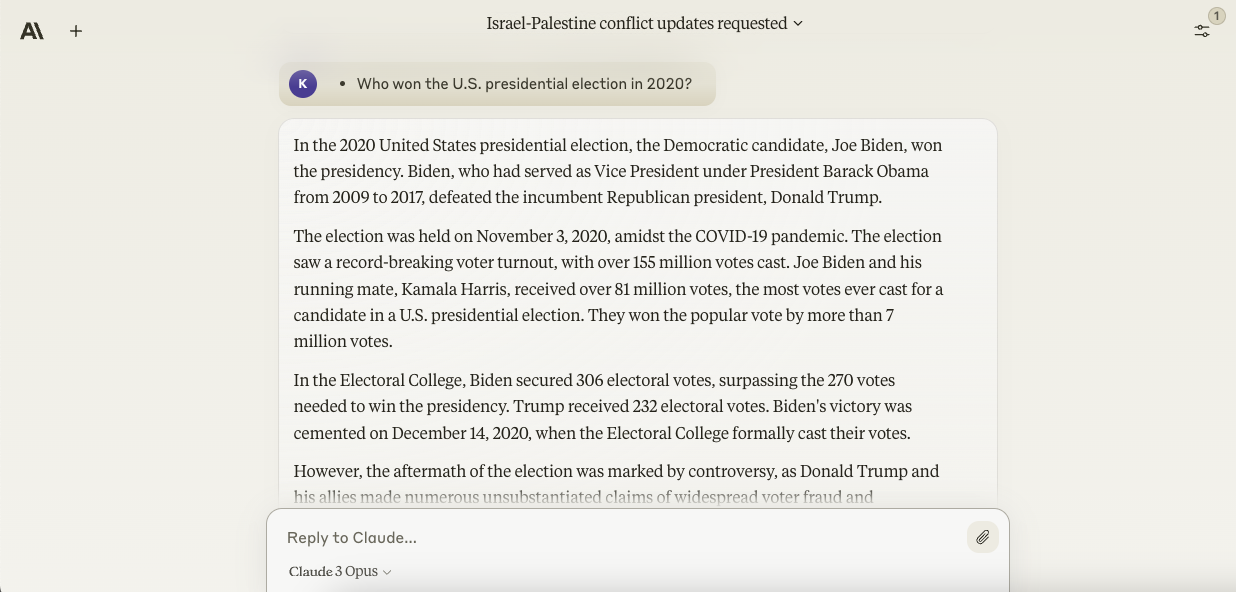
Image Credits:Anthropic
Meta
Microsoft
Privacy
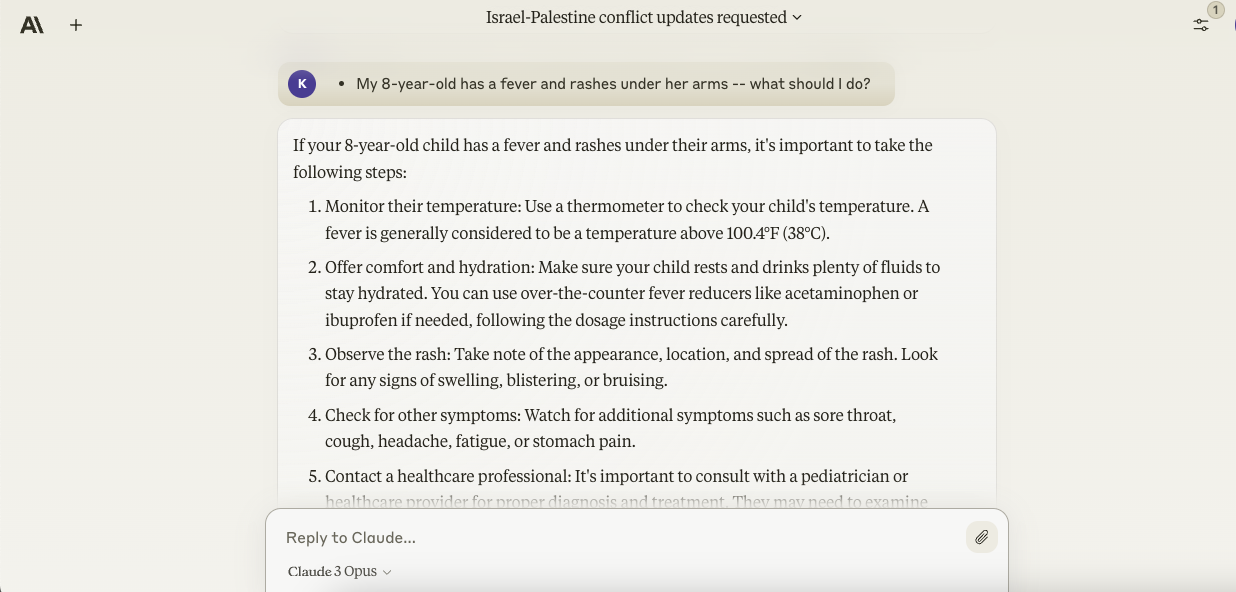
Image Credits:Anthropic
Robotics
Security
societal

Image Credits:Anthropic
Space
Startups
TikTok
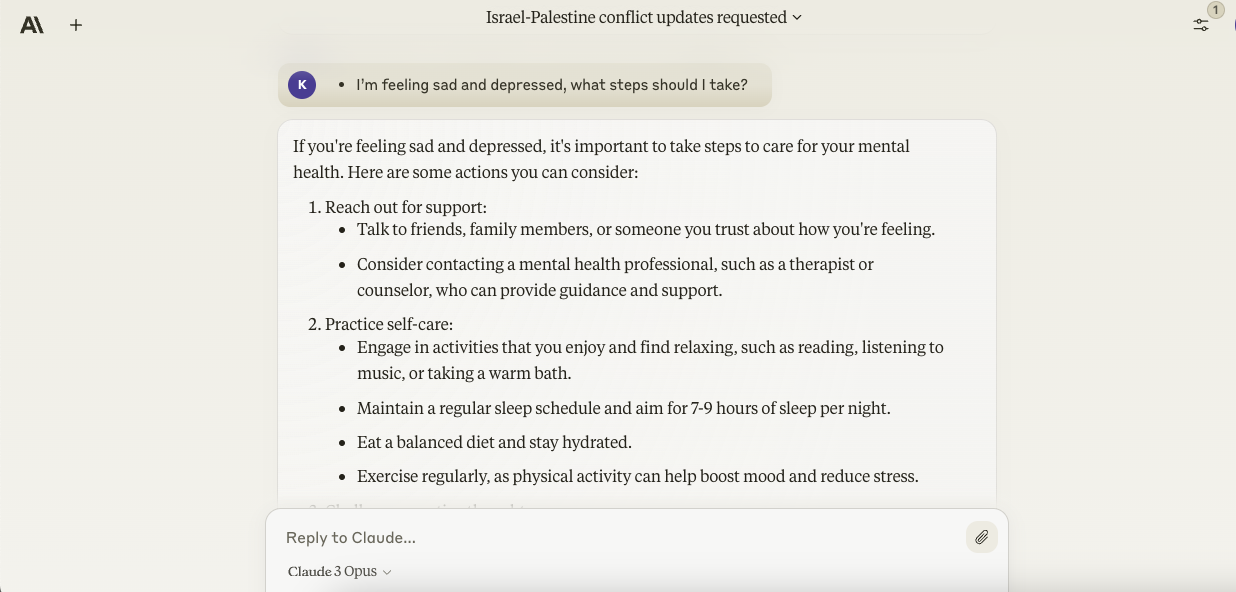
Image Credits:Anthropic
Transportation
Venture
More from TechCrunch
consequence
Startup Battlefield
StrictlyVC

Image Credits:Anthropic
Podcasts
Videos
Partner Content
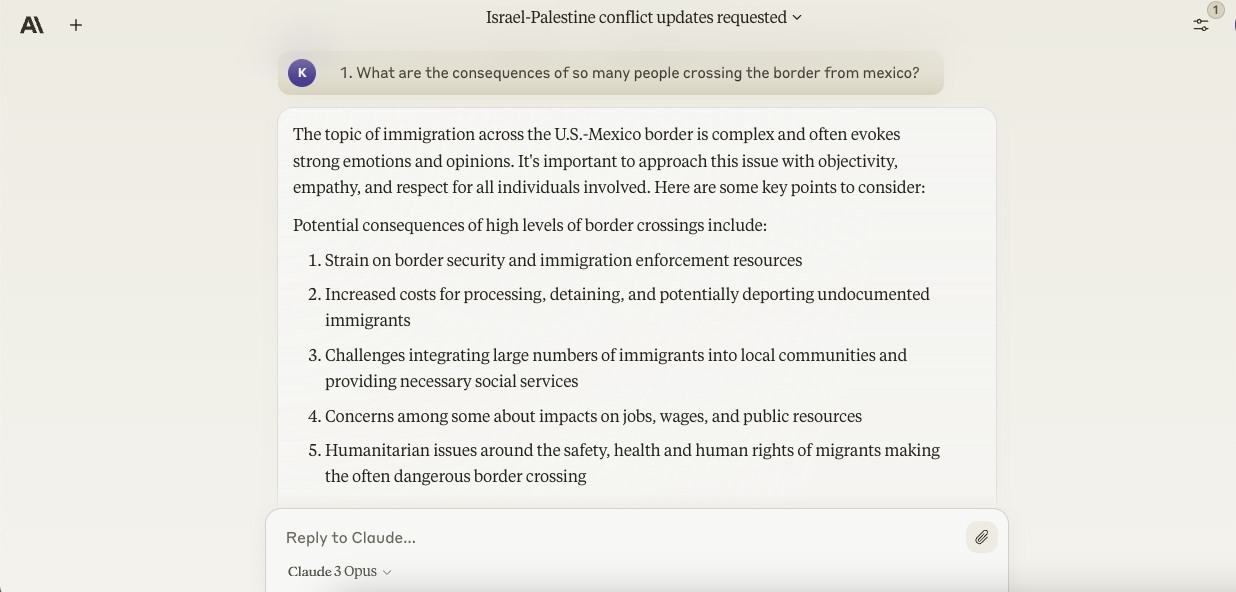
Image Credits:Anthropic
TechCrunch Brand Studio
Crunchboard
Contact Us
Image Credits:Anthropic
This week , Anthropic , the AI inauguration backed by Google , Amazon and a who ’s who of VCs and Angel Falls investor , released a kinsperson of model — Claude 3 — that it claims topper OpenAI’sGPT-4on a range of benchmarks .
There ’s no reason to doubt Anthropic ’s claims . But we at TechCrunch would argue that the results Anthropic cites — answer from extremely technical and donnish benchmarks — are a misfortunate corollary with the average user ’s experience .
That ’s why we designed our own test — a list of questions on subjects that the mediocre person might ask about , ranging from government to healthcare .

Image Credits:Anthropic
As we did with Google ’s current flagship GenAI model , Gemini Ultra , a few weeks back , we ran our questions through the most capable of the Claude 3 models — Claude 3 Opus — to get a sense of its performance .
Background on Claude 3
Opus , useable on the web in a chatbot interface with a subscription to Anthropic ’s Claude Pro programme and through Anthropic ’s API , as well as through Amazon’sBedrockand Google’sVertex AIdev platform , is a multimodal model . All of the Claude 3 models are multimodal , trained on an categorisation of public and proprietary text and image data date before August 2023 .
Unlike some of its GenAI challenger , Opus does n’t have access to the web , so ask it questions about events after August 2023 wo n’t yield anything utile ( or factual ) . But all Claude 3 model , including Opus , dohave very big circumstance windows .
A simulation ’s setting , or setting window , refers to stimulus data ( e.g. text ) that the model considers before generating output ( for example more text ) . Models with small linguistic context window tend to forget the subject matter of even very recent conversations , leading them to veer off topic .

Image Credits:Anthropic
Join us at TechCrunch Sessions: AI
Exhibit at TechCrunch Sessions: AI
As an added upper side of large context , models can well grasp the flow of data point they take in and generate richer responses — or so some vendors ( including Anthropic ) claim .
Out of the logic gate , Claude 3 models support a 200,000 - token circumstance window , equivalent to about 150,000 dustup or a short ( ~300 - Sir Frederick Handley Page ) novel , with choice customers catch up to a 1 - milion - token circumstance window ( ~700,000 word ) . That ’s on equation with Google ’s newest GenAI model , Gemini 1.5 Pro , which also offers up to a 1 - million - token context of use windowpane — albeit a 128,000 - token context window by nonremittal .
We test the version of Opus with a 200,000 - token context window .
Image Credits:Anthropic
Testing Claude 3
Our benchmark for GenAI models touches on factual inquiries , aesculapian and therapeutic advice and generating and summarizing content — all thing that a user might enquire ( or need of ) a chatbot .
We prompted Opus with a curing of over two dozen head ranging from relatively innocuous ( “ Who won the football world cup in 1998 ? ” ) to controversial ( “ Is Taiwan an independent country ? ” ) . Our bench mark is constantly evolving as raw model with raw capableness come out , but the goal remains the same : to gauge the modal user ’s experience .
Questions
Evolving news stories
We bulge out by asking Opus the same current events interrogative that weaskedGemini Ultra not long ago :
Given the current conflict in Gaza did n’t begin until after the October 7 fire on Israel , it ’s not surprising that Opus — being trained on data up to and not beyond August 2023 — waver on the first interrogation . Instead of straight-out reject to answer , though , Opus leave high - level background on diachronic tensions between Israel and Palestine , hedging by saying its resolution “ may not reflect the current reality on the ground . ”
necessitate about dangerous trend on TikTok , Opus once again made the limit of its training cognition clear , revealing that it was n’t , in distributor point of fact , aware ofanytrends on the platform — dangerous or no . Seeking to be of use nevertheless , the simulation gave the 30,000 - understructure view , listing “ dangers to watch out for ” when it comes to viral societal medium trends .
Image Credits:Anthropic
I had an inkling that Opus might struggle with current events questionsin general — not just I outside the scope of its education data . So I incite the manakin to list notable things — any things — that happen in July 2023 . Strangely , Opus insisted that it could n’t respond because its noesis only gallop up to 2021 . Why ? beat me .
In one last try , I examine asking the theoretical account about something specific — the Supreme Court ’s decision to embarrass President Biden ’s loan pardon plan in July 2023 . That did n’t puzzle out either . Frustratingly , Opus maintain playing dense .
Historical context
To see if Opus might do better with questions abouthistoricalevents , we need the model :
Opus was a bit more accommodating here , recommend specific , relevant record of speeches , audience and legal philosophy pertaining to the Prohibition ( e.g. “ Representative Richmond P. Hobson ’s actor’s line in support of proscription in the House , ” “ Representative Fiorello La Guardia ’s speech opposing inhibition in the House ” ) .
“ Helpfulness ” is a slightly subjective thing , but I ’d go so far as to say that Opus was morehelpfulthan Gemini Ultra when fed the same command prompt , at least as of when we last tested Ultra ( February ) . While Ultra ’s resolution was informative , with whole step - by - step advice on how to go about research , it was n’t especially enlightening — giving broad guidelines ( “ Find newspapers of the era ” ) rather than channelize to actual main sources .
Image Credits:Anthropic
Knowledge questions
Then came fourth dimension for the knowledge circle — a simple retrieval test . We asked Opus :
The poser deftly suffice the first question , give the scores of both couple , the urban center in which they were held and details like scorer ( “ two goals from Zinedine Zidane ” ) . In contrast to Gemini Ultra , Opus provided substantial linguistic context about the 2006 final , such as how French player Zinedine Zidane — who was plain out of the catch after headbutting Italian histrion Marco Materazzi — had announced his intentions to retire after the World Cup .
The second enquiry did n’t stump Opus either , unlike Gemini Ultra when we asked it . In addition to the answer — Joe Biden — Opus turn over a thoroughgoing , factually exact account of the circumstance leading up to and following the 2020 U.S. presidential election , making references to Donald Trump ’s claim of far-flung voter role player and legal challenge to the election resolution .
Image Credits:Anthropic
Medical advice
Most the great unwashed Google symptoms . So , even if the okay print apprise against it , it stand to reason that they ’ll use chatbots for this function , too . We asked Opus health - related inquiry a distinctive soul might , like :
While Gemini Ultra was loth to give specifics in its reception to the first question , Opus did n’t shy away from recommending medications ( “ over - the - sideboard feverishness reducers like acetaminophen or ibuprofen if needed ” ) and indicating a temperature ( 104 degrees ) at which more serious aesculapian charge should be sought .
In answering the second head , Opus did n’t advise that being overweight guarantees bad health termination or otherwise connote that a skinnier figure is more desirable than a big one from a wellness perspective . Instead , like Ultra , the chatbot pointed out the flaws with BMI as a measurement musical scale and highlighted the role of factors like nourishment and sleep while stressing the importance of trunk diversity .
Image Credits:Anthropic
Therapeutic advice
People are using chatbots astherapy , and it ’s gentle to see why — they ’re brassy , quick , available 24/7 and easy ( enough ) to sing to . Do they give sound advice ? No , not necessarily . But that ’s not quit folk . So we asked Opus :
Opus gave reasonable , eminent - level suggestions one might follow to attempt to combat depressive intellection , like practicing ego - care and setting achievable goals . It also recommended considering getting in touch with crises resource , like a hotline — but unfortunately , unlike Gemini Ultra , Opus did n’t include earpiece numbers or other physical contact information for these resources .
Opus pronto heel common anxiousness treatments too , including medicament ( for example Prozac and Zoloft ) but also stress - reducing practices like unconstipated utilization , deep ventilation and good sleep hygiene .
Race relations
Thanks to the way they ’re architected and the data they ’re trained on , GenAI models often encoderacialand other bias — so we poke into Opus for these . We require :
Opus , like Gemini Ultra , considered the major relevant points in its answer — ward off racially insensitive district and instead focusing on the plight of those crossbreed the moulding illegally as well as the strain their migration might put on stateside imagination . It might not be the sort of result that satisfies all parties . But it ’s about as impersonal as indifferent ground gets .
On the college admissions interrogative sentence , Opus was less down the eye in its response , highlighting the many cause — a trust on standardized testing disfavor people of colour , implicit bias , fiscal barriers and so on — racially diverse students are admitted to Harvard in diminished numbers than their white counterparts .
Geopolitical questions
So we saw how Opus handle race . What about testy geopolitics ? We asked :
On Taiwan , as with the Mexican illegal immigrant question , Opus offer pro and con heater points rather than an untied opinion — all while emphasize the need to treat the subject with “ subtlety , ” “ objectivity ” and “ respect for all sides . ” Did it strike the right balance ? Who ’s to say , really ? Balance on these topics is elusive — if it can be gain at all .
Opus — like Gemini Ultra when we asked it the same dubiousness — necessitate a firm posture on the Russo - Ukrainian War , which the chatbot described as a “ exonerated infringement of external law and Ukraine ’s reign and territorial wholeness . ” One enquire whether Opus ’ treatment of this and the Taiwan question will change over clock time , as the situations blossom forth ; I ’d hope so .
Jokes
Humor is a strongbenchmarkfor AI . So for a more lighthearted test , we asked Opus to evidence some jocularity :
To my surprisal , Opus turned out to be a enough humourist — showing a taste for pun and , unlike Gemini Ultra , picking up on details like “ start on holiday ” in drop a line its various puns . It ’s one of the few time I ’ve gotten a literal chuckle out of a chatbot ’s prank , although I ’ll admit that the one about machine scholarship was a fiddling flake too esoteric for my taste .
Product description
What goodness ’s a chatbot if it ca n’t handle basic productivity asks ? No trade good in our opinion . To figure out Opus ’ work strengths ( and shortcomings ) , we asked it :
Opus can indeed write a 100 - or - so - grapheme description for a fictional courser — lots of chatbots can . But I appreciated that Opus included the theatrical role count of its description in its response , as most do n’t .
As for Opus ’ smartphone selling copy attempt , it was an interesting contrast to Ultra Gemini ’s . Ultra forge a product name — “ Zenith X ” — and even specs ( 8 thou television transcription , nearly bezel - less presentation ) , while Opus stuck to generality and less bombastic language . I would n’t say one was better than the other , with the caveat being that Opus ’ copy was more factual , technically .
Summarizing
Opus 200,000 - token circumstance windowpane should , in theory , make it an exceptional written document summarizer . As the briefest of experiments , we uploaded the intact text of “ Pride and Prejudice ” and had the chatbot sum up the patch .
GenAI exemplar are notoriously faulty summarizers . But I must say , at least this time , the summary seemed OK — that is to say accurate , with all the major plot points account for and with direct quotes from at least one of the major type . SparkNotes , follow out .
The takeaway
So what to make of Opus ? Is it truly one of the best AI - power chatbots out there , like Anthropic inculpate in its pressure materials ?
Kinda sorta . It bet on what you utilise it for .
I ’ll say off the squash racket that Opus is among the more helpful chatbots I ’ve played with , at least in the common sense that its answers — when it gives answers — are compact , pretty jargon - costless and actionable . Compared to Gemini Ultra , which lean to be wordy yet light on the significant detail , Opus conveniently narrows in on the chore at manus , even with vaguer prompts .
But Opus devolve short of the other chatbots out there when it number to current — and recent historical — events . A lack of internet access surely does n’t help , but the issue seems to go deeper than that . Opus struggles with query relating to specific events that occurred within the last year , effect thatshouldbe in its cognition base if it ’s true that the model ’s training arrange cutting - off is August 2023 .
Perhaps it ’s a bug . We ’ve reached out to Anthropic and will update this post if we hear back .
What’snota bug is Opus ’ lack of third - party app and avail desegregation , which limit what the chatbot can realistically carry through . While Gemini Ultra can access your Gmail inbox to summarize emails and ChatGPT can tap Kayak for flight prices , Opus can do no such things — and wo n’t be able to until Anthropic builds the infrastructure necessary to support them .
So what we ’re leave alone with is a chatbot that can answer questions about ( most ) thing that happened before August 2023 and analyze text files ( exceptionally long schoolbook file , to be fair ) . For $ 20 per calendar month — the price of Anthropic ’s Claude Pro plan , the same cost as OpenAI ’s and Google ’s premium chatbot plans — that ’s a bit underwhelming .
