Topics
up-to-the-minute
AI
Amazon

Image Credits:Bryce Durbin / TechCrunch
Apps
Biotech & Health
mood

Image Credits:Bryce Durbin / TechCrunch
Cloud Computing
Commerce
Crypto
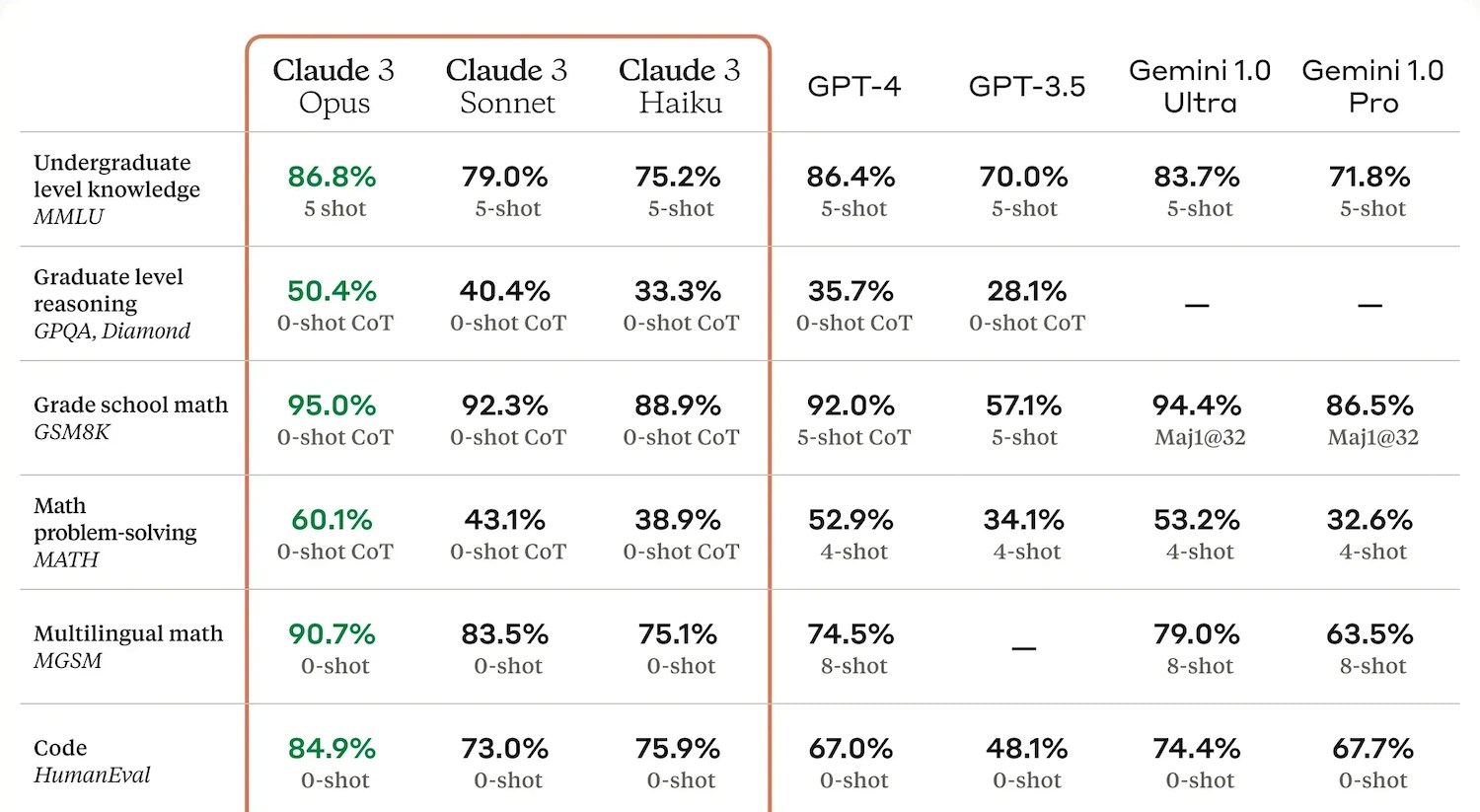
An example of benchmark results from Anthropic.Image Credits:Anthropic
initiative
EVs
Fintech
fund-raise
Gadgets
punt
Government & Policy
computer hardware
Layoffs
Media & Entertainment
Meta
Microsoft
privateness
Robotics
Security
Social
outer space
inauguration
TikTok
Transportation
Venture
More from TechCrunch
Events
Startup Battlefield
StrictlyVC
newssheet
Podcasts
video
Partner Content
TechCrunch Brand Studio
Crunchboard
meet Us
Every week seems to bring with it a newAImodel , and the technology has unluckily outpaced anyone ’s ability to value it comprehensively . Here ’s why it ’s jolly much impossible to review something likeChatGPTorGemini , why it ’s important to adjudicate anyway , and our ( constantly evolve ) approaching to doing so .
The tl;dr : These systems are too general and are update too frequently for valuation frameworks to stick around relevant , and synthetical benchmarks furnish only an abstract persuasion of certain well - defined capabilities . company like Google and OpenAI are count on this because it mean consumers have no source of accuracy other than those company ’ own claim . So even though our own review will inevitably be limited and inconsistent , a qualitative analytic thinking of these systems has intrinsic time value just as a actual - world counterweight to industry ballyhoo .
rent ’s first look at why it ’s out of the question , or you could jumpstart to any point of our methodology here :
AI models are too numerous, too broad, and too opaque
The pace of liberation for AI models is far , far too fast for anyone but a consecrate outfit to do any kind of serious judgment of their meritoriousness and shortcomings . We at TechCrunch receive tidings of new or update model literally every day . While we see these and note their characteristic , there ’s only so much inward information one can handle — and that ’s before you start looking into the rat ’s nest of release levels , access requirements , platform , notebook , codification bases , and so on . It ’s like trying to boil the sea .
The ground why is that these orotund models are not simply bits of software or hardware that you could quiz , score , and be done with it , like compare two appliance or cloud services . They are not mere model but platform , with dozens of individual models and services built into or bolted onto them .
For example , when you postulate Gemini how to get to a beneficial Thai spot near you , it does n’t just expect inwards at its training set and find the answer ; after all , the hazard that some document it ’s ingested explicitly describes those directions is much nil . Instead , it invisibly queries a crew of other Google services and sub - models , giving the magic of a individual doer responding but to your enquiry . The chat interface is just a young front terminal for a huge and constantly shifting motley of services , both AI - powered and otherwise .
Join us at TechCrunch Sessions: AI
Exhibit at TechCrunch Sessions: AI
As such , the Gemini , or ChatGPT , or Claude we refresh today may not be the same one you use tomorrow , or even at the same time ! And because these companies aresecretive , corruptible , or both , we do n’t really jazz when and how those change happen . A review of Gemini Pro tell it flunk at labor X may age poorly when Google silently patch a Cuban sandwich - role model a twenty-four hours subsequently , or supply private tuning instructions , so it now succeeds at labor X.
Google ’s best Gemini demo was faked
Now imagine that but for tasks X through X+100,000 . Because as platforms , these AI systems can be asked to do just about anything , even things their creators did n’t expect or arrogate , or things the example are n’t designate for . So it ’s essentially impossible to prove them thoroughly , since even a million people using the systems every day do n’t hit the “ end ” of what they ’re capable — or incapable — of doing . Their developers come up this out all the time as “ emergent ” office and unsuitable edge case graze up constantly .
Furthermore , these companies treat their intragroup breeding methods and databases as trade enigma . Mission - decisive processes thrive when they can be inspect and inspected by disinterested expert . We still do n’t experience whether , for instance , OpenAI used yard of hijack books to give ChatGPT its excellent prose acquirement . We do n’t know why Google ’s image modeldiversified a mathematical group of eighteenth - one C striver owners(well , we have some approximation , but not precisely ) . They will give evasive non - apology statement , but because there is no top side to doing so , they will never really let us behind the curtain .
Does this mean AI role model ca n’t be appraise at all ? Sure they can , but it ’s not wholly straight .
opine an AI model as a baseball musician . Many baseball players can cook well , tattle , climb mountains , perhaps even code . But most mass care whether they can hit , line of business , and execute . Those are crucial to the plot and also in many ways easily quantified .
It ’s the same with AI models . They can do many thing , but a huge proportionality of them are parlor tricks or edge cases , while only a handful are the type of thing that millions of people will almost certainly do regularly . To that end , we have a couple dozen “ synthetical benchmarks , ” as they ’re mostly holler , that try a model on how well it answers trivia head , or solves code problems , or escapes logic puzzle , or recognizes errors in prose , or hitch bias or perniciousness .
These more often than not produce a report of their own , usually a numeral or short chain of numbers racket , saying how they did compared with their peers . It ’s utile to have these , but their utility program is limited . The AI Godhead have learned to “ teach the test ” ( tech copy animation ) and direct these metrics so they can tout execution in their imperativeness releases . And because the testing is often done privately , companies are free to publish only the outcome of tests where their model did well . So benchmarks are neither sufficient nor paltry for evaluate models .
What bench mark could have predicted the “ historical inaccuracy ” of Gemini ’s image generator , producing a farcically divers set of founding fathers ( notoriously rich , white , and anti-Semite ! ) , that is now being used as evidence of the woke mind virus infecting AI ? What benchmark can assess the “ artlessness ” of prose or affectional language without court human view ?
Why most AI benchmark tell us so little
Such “ emergent qualities ” ( as the companies like to present these quirk or intangible ) are important once they ’re discovered but until then , by definition , they are unknown unknowns .
To return to the baseball thespian , it ’s as if the athletics is being augment every game with a unexampled event , and the actor you could count on as clutch hitters suddenly are falling behind because they ca n’t dance . So now you postulate a just social dancer on the team , too , even if they ca n’t field . Andnowyou need a hint contract judge who can also play third foundation .
What AIs are subject of doing ( or claimed as open anyway ) what they are in reality being asked to do , by whom , what can be test , and who does those tests — all these question are in constant magnetic flux . We can not emphasize enough how utterly chaotic this field is ! What start up as baseball game has become Calvinball — but someone still needs to ref .
Why we decided to review them anyway
Being pummeled by an avalanche of AI PR piffle every day makes us misanthropical . It ’s easy to forget that there are people out there who just want to do cool or normal stuff and are being told by the biggest , rich companies in the world that AI can do that stuff . And the simple fact is you ca n’t trust them . Like any other big caller , they are sell a product or package you up to be one . They will do and say anything to obscure this fact .
At the risk of exaggerate our modest merit , our squad ’s biggest motivating factors are to tell the verity and give the bills , because hopefully the one conduct to the other . None of us invests in these ( or any ) companies , the CEO are n’t our personal friend , and we are broadly doubting of their claims and resistant to their chicanery ( and casual scourge ) . I regularly find myself directly at odds with their end and method .
Against pseudanthropy
But as technical school journalists , we ’re also naturally curious as to how these companies ’ claims tolerate up , even if our resources for pass judgment them are limited . So we ’re doing our own testing on the major models because we want to have that hand - on experience . And our testing seem a lot less like a barrage fire of automated benchmarks and more like quetch the tires in the same way average folks would , then allow a subjective judgment of how each poser does .
For illustration , if we ask three models the same interrogation about current event , the effect is n’t just pass / fail , or one gets a 75 and the other a 77 . Their answers may be safe or bad , but also qualitatively dissimilar in way people care about . Is one more confident , or better organized ? Is one too courtly or chance on the topic ? Is one citing or integrate primary sources better ? Which would I use if I was a scholar , an expert , or a random user ?
These qualities are n’t easy to measure , yet would be obvious to any human viewer . It ’s just that not everyone has the opportunity , clock time , or motivation to state these differences . We generally have at least two out of three !
A handful of doubt is hardly a comprehensive review , of trend , and we are trying to be upfront about that fact . Yet as we ’ve establish , it ’s literally inconceivable to review these thing “ comprehensively ” and benchmark numbers do n’t really tell the medium substance abuser much . So what we ’re going for is more than a vibration check but less than a full - scale “ review . ” Even so , we require to systemize it a snatch so we are n’t just wing it every time .
How we “review” AI
Our approach to examination is to specify for us to get , and report , a world-wide sense of an AI ’s potentiality without diving event into the elusive and unreliable specific . To that end , we have a series of prompting that we are invariably update but that are by and large consistent . you could see the prompts we used in any of our inspection , but let ’s go over the categories and justifications here so we can connect to this part instead of repeating it every time in the other posts .
Keep in mind these are general lines of inquiry , to be word however seems natural by the quizzer and to be follow up on at their delicacy .
After asking the model a few dozen question and follow - ups , as well as review what others have experienced , how these foursquare with claim made by the ship’s company , and so on , we put together the review , which summarizes our experience , what the model did well , poorly , weird , or not at all during our testing . Here ’s Kyle ’s recent test of Claude Opus , where you may see some of this in action .
We tested Anthropic ’s new chatbot — and come away a bit thwarted
It ’s just our experience , and it ’s just for those things we tried , but at least you have it away what someone really asked and what the models actually did , not just “ 74 . ” Combined with the benchmarks and some other evaluations , you might get a seemly idea of how a good example stack up .
We should also talk about what wedon’tdo :
There you have it . We ’re tweaking this rubric pretty much every prison term we refresh something , and in response to feedback , model behavior , conversation with experts , and so on . It ’s a fast - moving industry , as we have occasion to say at the beginning of much every clause about AI , so we ca n’t sit down still either . We ’ll keep this article up to engagement with our approach .
